Artificial Neural Networks - Part 1: Foward Propagation
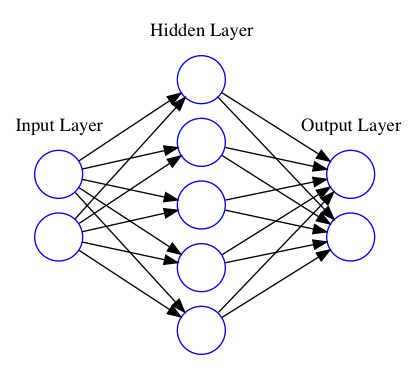
In the Python syntax, the activation function and the matrix multiplication between the Input and Hidden Layers can be written as,
import numpy as np
def
sigmoid(x):
"""
Sigmoid activation function
"""
if deriv == False:
return 1.0 / (1.0 + np.exp(-x))
else:
sigma = 1.0 / (1.0 + np.exp(-x))
return sigma * (1.0 - sigma)
# Input -> Hidden Layer
z1 = X.dot(W1) + b1
a2 = sigmoid(z1, deriv = False)
Other activation functions in Python can be found in the link to my GitHub below.
Similar procedure between the Input and Hidden Layers is done now between the Hidden Layer and the Output Layer. Note that now we use the output of the hidden layer \(a_2\) as the new input. Thus,
$$a_3 = softmax(a_2 * W_2 + b_2)$$
Between the Hidden Layer and the Output Layer, we just use a different activation function. Here we use the softmax, which is a good choice for probability classifications. It can be written as,
$$ softmax(x) = \frac{e^x}{\sum_i e^{x_i}}$$
In Python syntax, it is defined as the the softmax routine,
def softmax(x):
"""
Softmax activation function
"""
exp_x = np.exp(x)
return exp_x / exp_x.sum(axis=1, keepdims=True)
# Hidden -> Output Layer
z2 = a2.dot(W2) + b2
a3 = softmax(z2)
Remember that the dimension of \(a_2\) is (\(n_{obj}, n_{hidden})\) and the weights and bias between the Hidden and Ouput Layers are represented as \(W_2\) and \(b_2\). For the matrix multiplication, their matricial dimensions are (\(n_{hidden}, n_{output})\) and (\(n_{output}, 1)\), respectively. The value \(n_{output}\) represents the number of values atributed to each object in the Output Layer. This can be considered as classes or regression values. For instance, in case of bimodal classification, the output array length is 2 for each object in the training sample. In addition, it can be also considered as proabilities of this element to belong to classes, e.g., \([0.25, 0.75]\).
How many nodes should my ANN have? And how about the number of hidden layers? It really depends on how complex your data is. If you increase the number of nodes in the Hidden Layer, your model will be able to fit more complex and non-linear data. However, it will be more affected by overfitting, which is namely when your model only works on your training sample and fails on the test or any other sample. That's why it is so important to always evaluate the performance of your code with an independent (but representative) sample.
Increasing the number of hidden layers will consequently make your model more complex but you should think carefully before increasing the complexity of the ANN. Again, the overfitting can kill all your performance showing disapointing results on other samples. The increasing complexity also increases the computational time, particularly if your training sample is large enough. It can increase a lot your computational time, being most of time inpractical using an ordinary computer.
It is important to know how ANNs work but all this process above is already optimized by several packages in Python and R. Some examples are represented by Keras, Tensorflow and Theano. Some nice explanations of how ANN works are also in Data Science and Machine Learning blogs, then check the references below. If you want the full code of this post for didatic purposes, please check my GitHub - Neural Network from Scratch using the make_moons dataset. This post was just half of the story, the next part is the Neural Networks - Part 2: BackPropagation . If you have comments/suggestions about this post, please send me an e-mail.
Some references: